Research Activities
— CAD Algorithms & Tools for Physical Design
— Resource Virtualization & Rapid Prototyping
— Computer Vision for Space Applications
— Internet-of-Things (IoT) & CyberPhysical Systems (CPS)
— Network-on-Chip Architectures
— Fault-Tolerance & Reliability Improvement
Affiliated Member
a


a
Participate to University Programs & Collaborations
a
Access to multiple industrial tools and platforms in order to support research and academic activities.




CAD Algorithms & Tools for Physical Design
Next you can find some open-source tools for supporting the design of reconfigurable architectures and mapping digital designs to island-style FPGA platforms.
a
2D/3D MEANDER Framework
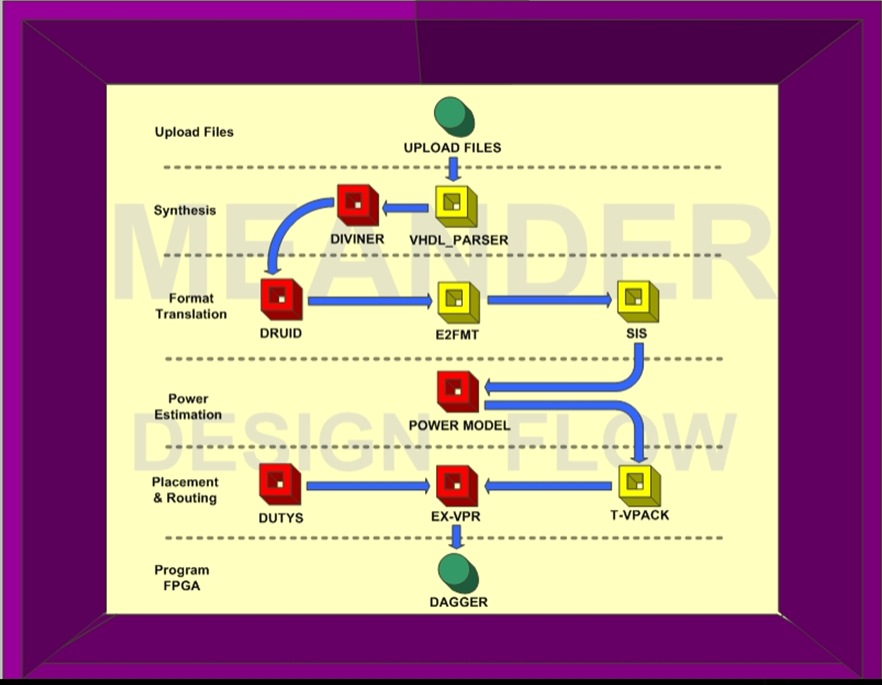
MEANDER framework is an open-source toolset for supporting the architecture-level exploration targeting FPGA devices. The framework was initially developed as deliverable from the AMDREL project (funded by EU) in order to support the design and programming of reconfigurable hardware (AMDREL FPGA device). This flow is also used for educational purposes, since it enables students/researchers to study the impact of different architectural selections.
Supported features for the 3D MEANDER Framework:
- Multiple algorithms for netlist partitioning, partition to layer assignment, placement and routing algorithms.
- Architecture-level exploration for different 3-D FPGAs
- Multiple bonding technologies (i.e., TSV, wirebonding, F2F)
- Alternative stacking technologies (i.e., PiP, PoP, Wafer-on-Wafer, Die-on-Wafer)
Reference Paper
Web-based execution of 2D MEANDER Framework
Request 2D/3D MEANDER Framework tools
a
3D-P&R: Machine Learning-aware P&R Algorithm Targeting 3D FPGAs
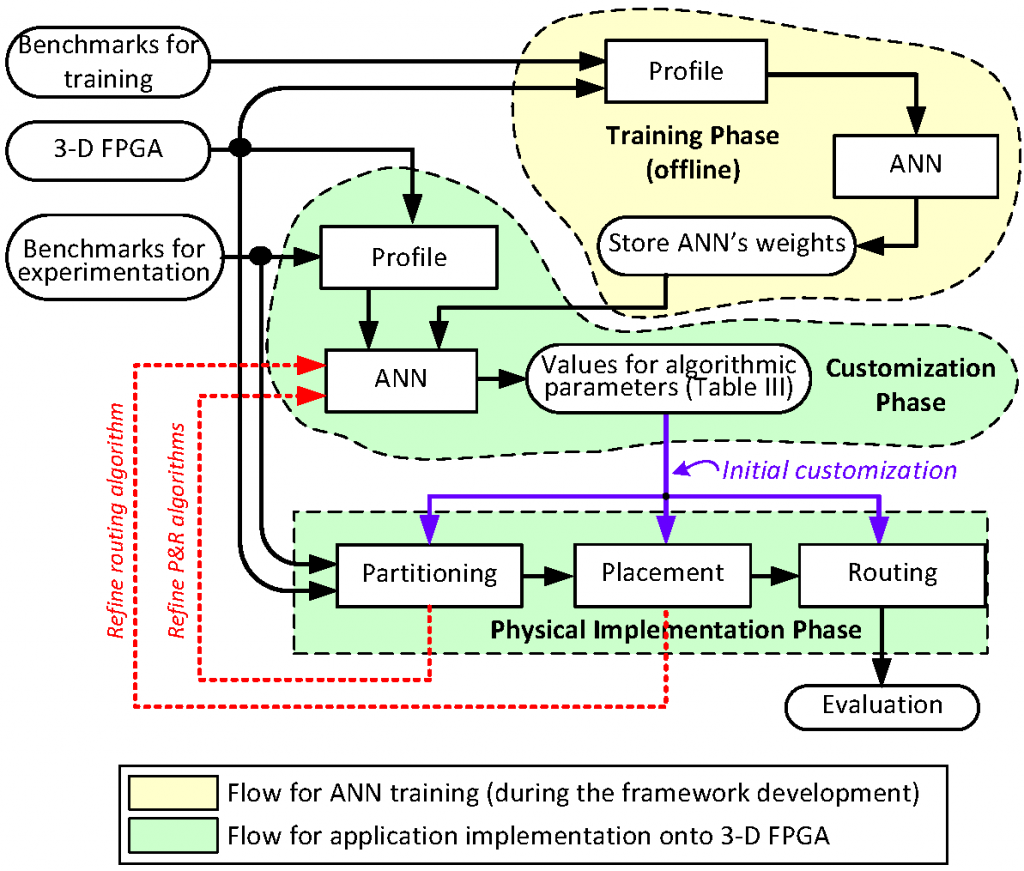
The complexity of digital designs imposes that CAD algorithms are getting harder and slower. This article introduces a framework for application implementation onto 3-D reconfigurable architectures. In contrast to existing approaches, the proposed solution is customizable according to constraints posed by the application and the target 3-D device in order to improve performance metrics.
Supported features:
- Multiple algorithms for netlist partitioning, partition to layer assignment, placement and routing algorithms.
- Flexible cost functions defined by designers
- Multiple connections types (i.e., buses, point-to-point, network-on-chip, or any combination)
- Rather than providing the optimal solution, it also gives all the Pareto solutions that trade-off the design parameters
a
REMAP: Framework for designing approximate computing kernels targeting hardware accelerators (FPGAs)
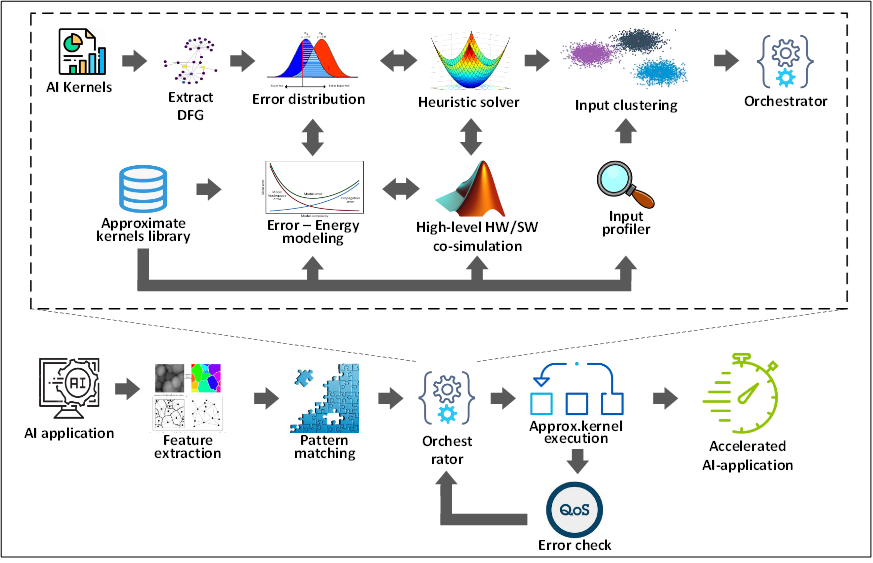
Leveraging the inherent error resilience of a large number of application domains, approximate computing is established as an efficient design alternative to improve their energy profile. The proposed solution relies on a repository with customizable templates of approximate kernels per application’s IP that are configured (fine-tuned) at run-time depending on application’s workload. By trading-off accuracy with energy consumption it is feasible to achieve real-time analysis for large data volumes. The configuration task is orchestrated by a run-time execution controller which monitors application’s workload in order to select the most suitable approximation kernel.
a
GENESIS: FPGA Placement based on Genetic Algorithm
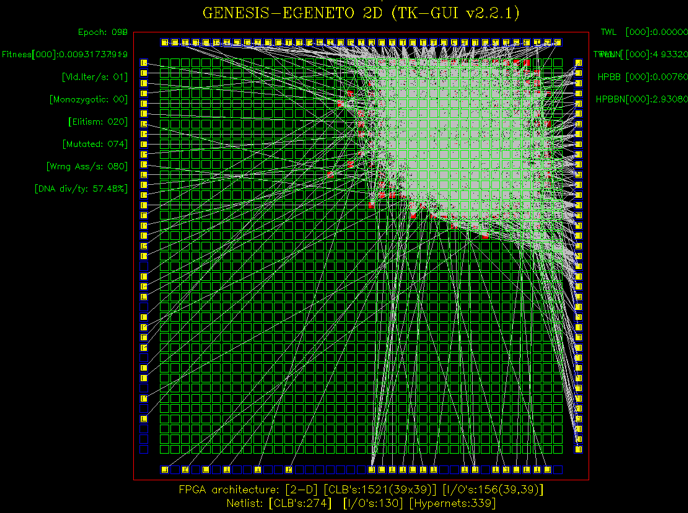
Placement is though as the most time-consuming processes in physical implementation flows for reconfigurable architectures, while it highly affects the quality of derived application implementation, as it has impact on the maximum operating frequency. GENESIS is a software-supported placer, based on genetic algorithm, targeting to FPGAs. Rather than relevant approaches which are executed sequentially, the new placer exhibits inherent parallelism, which can benefit from multi-core processors.
a
ANT3D: Simultaneous Partitioning and Placement for 3D FPGAs
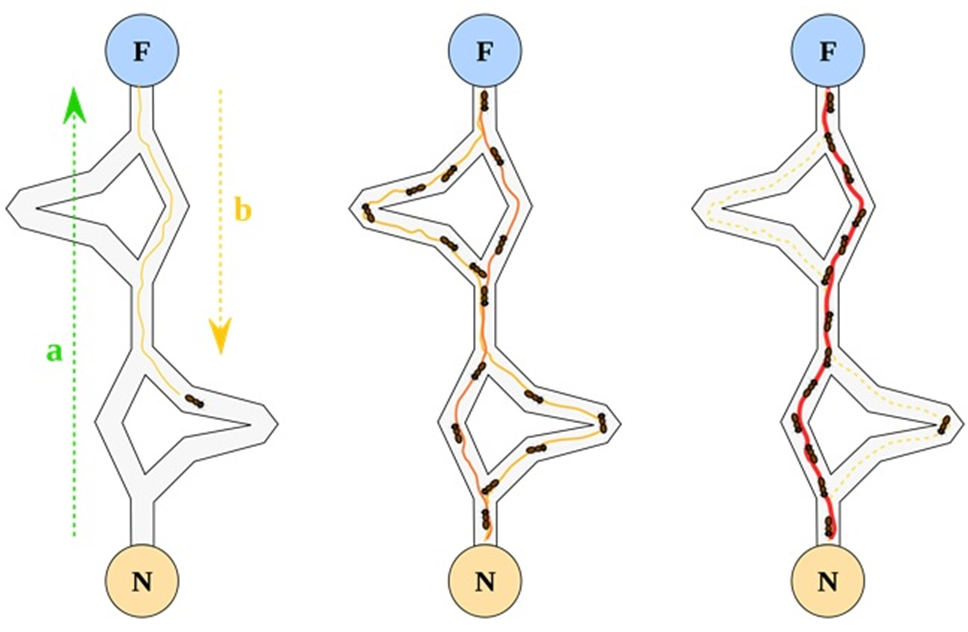
ANT3D is a novel netlist partitioning and placement algorithm targeting 3-D reconfigurable architectures. The algorithm relies on the Ant Colony Optimization (ACO) engine and simulates the foraging behavior of certain ant species which use a chemical compound called pheromone, in order to mark favorable paths for the subsequent ants to follow. The introduced implementation incorporates concepts from both the MAXMIN Ant System (MMAS) and the Ant Colony System (ACS).
a
Just-in-Time (JiT) Compilation for FPGAs
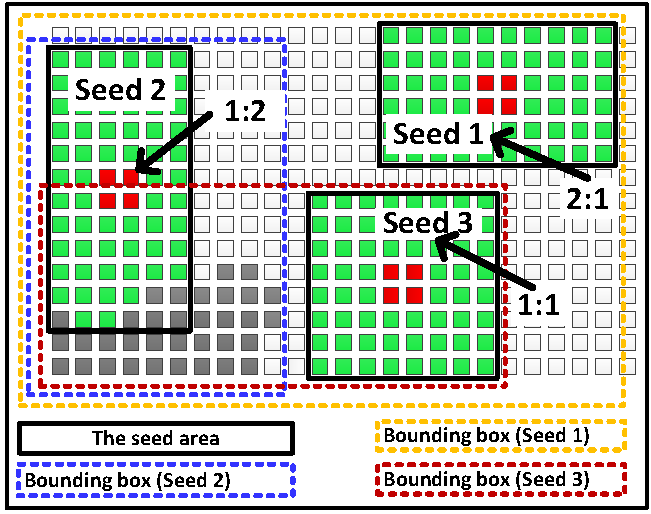
The execution runtime usually is a headache for designers performing application mapping onto reconfigurable architectures. Techniques that accelerate core CAD algorithms can bring about important changes in product design times for these applications, whereas many designers may be willing to trade off some quality of the solution for an improved runtime of the CAD tools. This software-supported framework targets to provide fast application implementation onto reconfigurable architectures with a Just-In-Time (JIT) compilation framework. Apart from reducing compilation times, the proposed solution addresses also the challenge related to device fragmentation, as it has considerable impact to the performance of upcoming applications.This task becomes far more savage for high-density FPGAs since over the time, as a partially reconfigurable device loads and unloads configurations, the hardware resources are likely to become fragmented.
a
DMM4FPGA: Dynamic Memory Management for HLS at Xilinx FPGAs
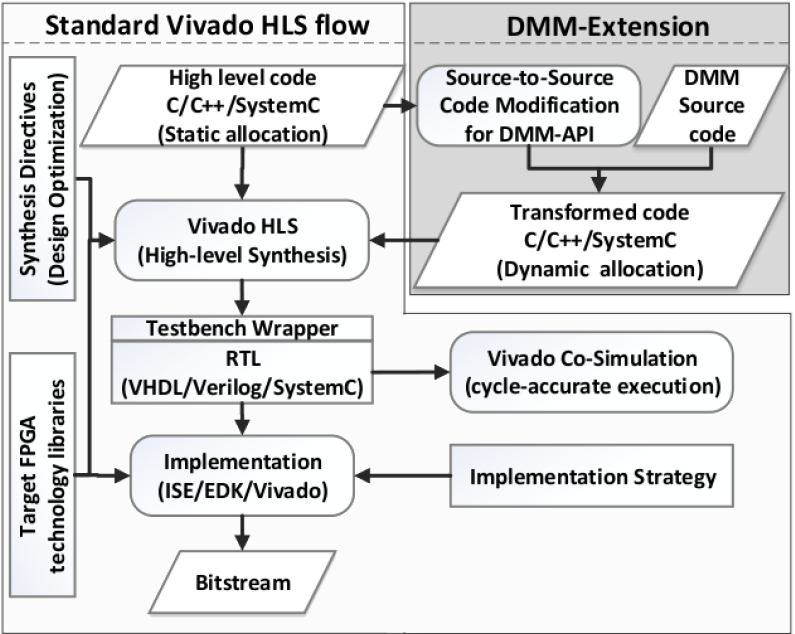
Many-Accelerator (MA) systems have been introduced as a promising architectural paradigm that can boost performance and improve power of general-purpose computing platforms. This framework focuses on the problem of resource under-utilization, i.e. Dark Silicon, in FPGA-based MA platforms. Recognizing that static memory allocation (the de-facto mechanism supported by modern design techniques and synthesis tools) forms the main source of memory-induced Dark Silicon, the DMM4FPGA tool extends conventional High Level Synthesis (Xilinx Vivado HLS) with dynamic memory management (DMM) features, enabling accelerators to dynamically adapt their allocated memory to the runtime memory requirements, thus maximizing the overall accelerator count through effective sharing of FPGA’s memories resources.
Reference Paper
Presentation of DMM-FPGA
Request software tool
a
Algorithmic and memory optimizatrion on multiple application mapping onto FPGA
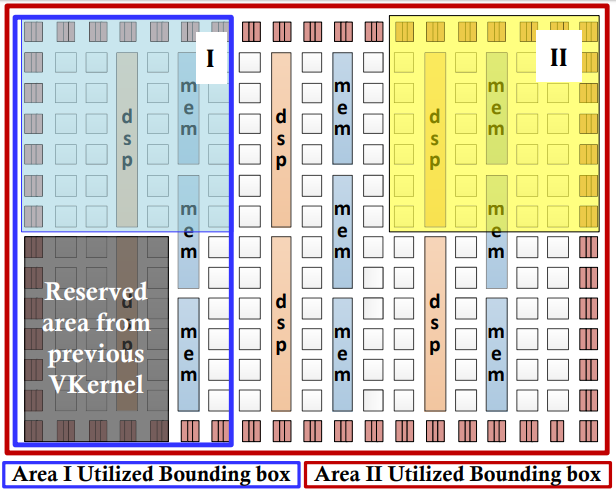
FPGAs offer a low power flexible accelerator alternative due to their inherent parallelism. Device reprogrammability, although its their key feature, it is used almost exclusively on design time due to the constrains imposed by the modern CAD tools that require even days to run and tens of GB of RAM. This toolset enables effective utilization of FPGAs on run-through a novel software-supported methodology that enables multiple applications to be mapped onto heterogeneous FPGAs. With the use of a floorplanning step, memory optimizations and custom memory allocators, the software tool alleviates the constrains imposed by CAD tools, and provides a proof of concept that application mapping onto FPGAs can be done even under run-time constratints.
a
Resource Virtualization & Rapid Prototyping
Next you can find some open-source tools for supporting the resource virtualization task for ASICs/FPGAs towards enabling Rapid Prototyping and Hardware-in-the-Loop.
a
Plug&Chip: Rapid Prototyping Framework
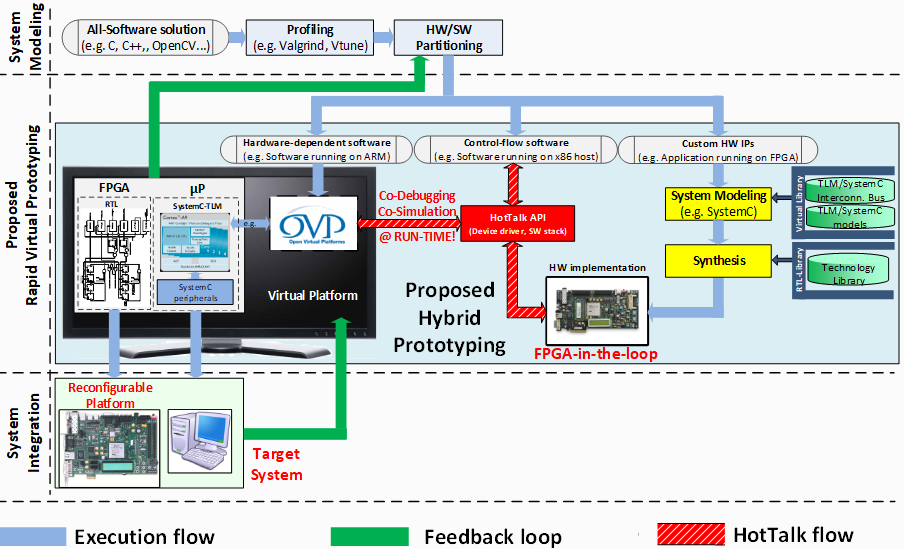
In the embedded system domain there is a continuous demand towards providing higher flexibility for application development. This trend strives for virtual prototyping solutions capable of performing fast system simulation. Among other benefits, such a solution supports concurrent hardware/software system design by enabling to start developing, testing, and validating the embedded software substantially earlier than has been possible in the past. Towards this direction, throughout this article we introduce a new framework, named Plug&Chip, targeting to support rapid prototyping of 2D and 3D digital systems. In contrast to other relevant approaches, our solution provides higher flexibility by enabling incremental system design, while also handling platforms developed with the usage of 3D integration technology.
Reference Paper
Demo for Plug&Chip (performance improvement for CV algorithm)
Request software tool
a
Virtual FPGA Platform
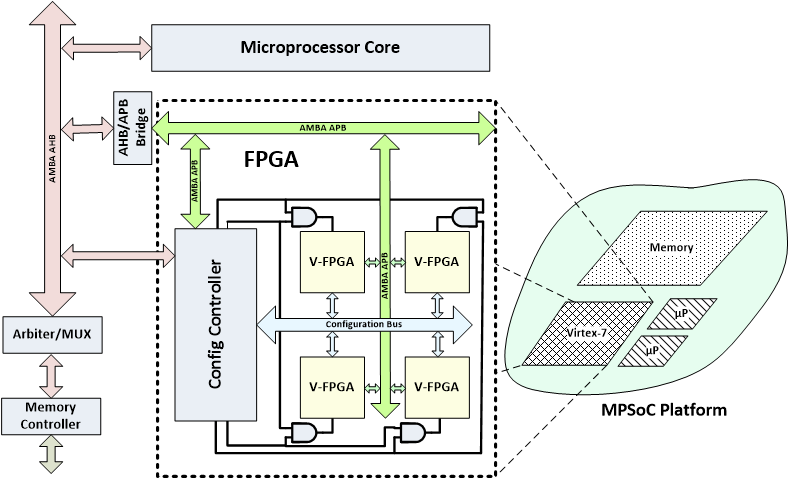
The virtual FPGA (V-FPGA) architecture is an island-style FPGA described in reusable VHDL and mapped onto Alter Stratix FPGA devices. V-FPGA is realized as virtual reconfigurable hardware upon a traditional off-the-shelf FPGA device. Since the architectural properties (e.g., the LUT size and the number of LUTs per slice) of each V-FPGA are easily customizable at design time (through a graphical user interface) depending on the application’s requirements, the employed V-FPGA can be considered an optimized application-specific platform. The target platform includes also a microprocessor core, a configuration controller, some off-chip memories, and buses for on-chip communication and configuration. The programming of V-FPGAs is performed with CAD tools describe at the “CAD Algorithms & Tools for Physical Design” Section.
Framework for Rapid Prototyping Many-accelerator SoCs
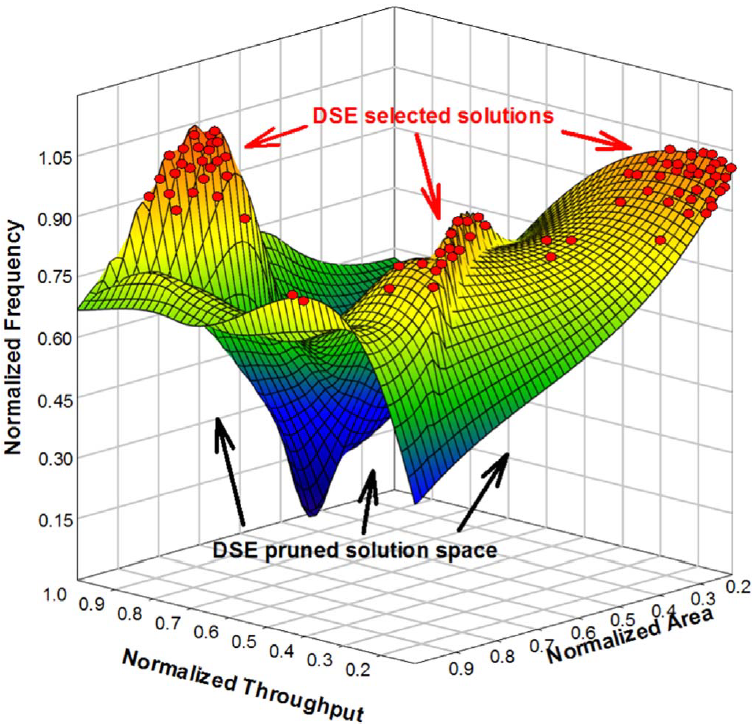
The recent advent of many-accelerator systems-on-chip (SoC), driven by the need for maximizing throughput and power efficiency, has led to an exponential increase in the hardware/software co-design complexity. The reason of this increase is that the designer has to explore a vast number of architectural parameter combinations for each single accelerator, as well as inter-accelerator configuration combinations under specific area, throughput, and power constraints, given that each accelerator has different computational requirements. In such a case, the design space size explodes. Thus, existing design space exploration (DSE) techniques give poor-quality solutions, as the design space cannot be adequately covered in a fair time. This problem is aggravated by the very long simulation time of the many-accelerator virtual platforms (VPs). This framework addresses these design issues by (a) presenting a virtual prototyping solution that decreases the exploration time by enabling the evaluation of multiple configurations per VP simulation and (b) proposing a DSE methodology that efficiently explores the design space of many-accelerator systems.
a
Computer Vision for Space Applications
Next, you can find IP kernels that accelerate computational intensive tasks with the usage of FPGA & GPU platforms.
a
Hardware Implementation of Computer Vision Algorithms for Autonomous Rover Navigation
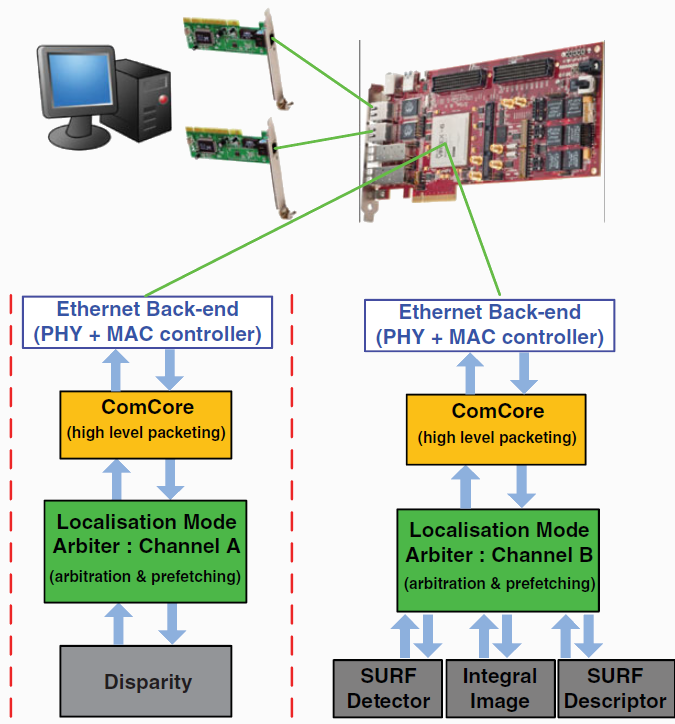
Mars exploration is expected to remain a focus of the scientific community in the years to come. A Mars rover should be highly autonomous because communication between the rover and the terrestrial operation center is difficult, and because the vehicle should spend as much of its traverse time as possible moving. Autonomous behavior of the rover implies that the vision system provides both a wide view to enable navigation and three‐dimensional (3D) reconstruction, and at the same time a close‐up view ensuring safety and providing reliable odometry data. This work deals with the physical design of rover’s vision system onto Xilinx Virtex-6 FPGA board.
Reference Paper
Demo for Rover Localization
Request software tool
a
Internet-of-Things and CyberPhysical Systems
Open source software tools for supporting multi-objective optimizations for IoT and CPS platforms.
a
SmartTemp: Rapid Prototyping of Decision-Making for Smart Thermostats
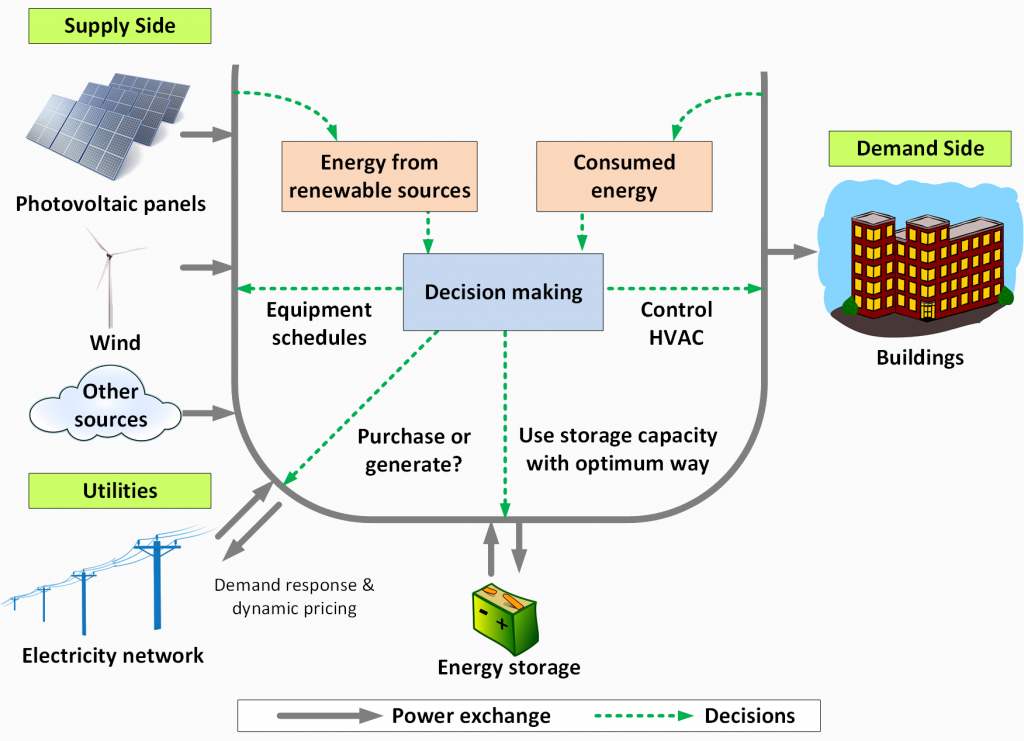
The control of CyberPhysical Systems (CPSs) often results in very high-order models imposing great challenges to the analysis and design problems. This algorithm supports the decision-making for these systems.
a
ApoDOSIS: Distributed Auction Mechanism for Energy Trading in Micro-Grids
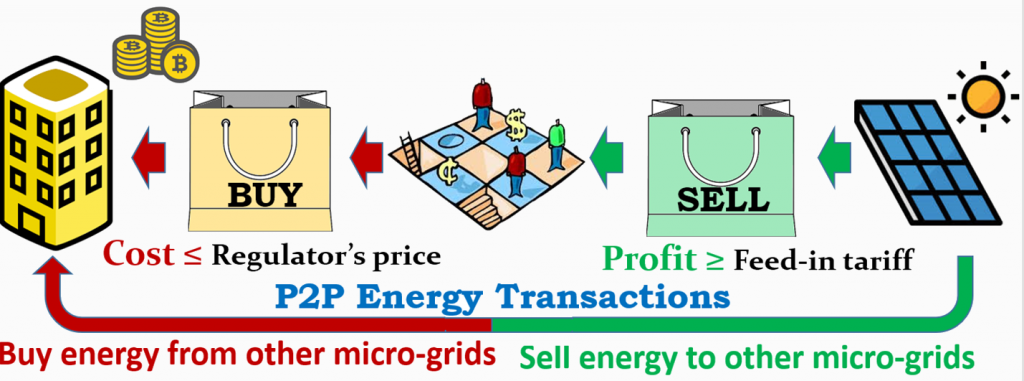
With the increasing connection of distributed energy resources, traditional energy consumers are becoming prosumers, who can both dissipate and generate energy in a smart-grid environment. This enables the wide adoption of dynamic pricing scheme, where demand and price forecast are applied for estimating energy cost and loads scheduling. The ApoDOSIS framework is a Peer-to-Peer (P2P) platform, as well as a light-weighted system orchestrator based on game theory, which supports the task of energy trading in distributed manner.
a
Network-on-Chip Architectures
Open-source tool for digital design of NoC architectures targeting Xilinx FPGAs.
a
FlexNoc: Design Network-on-Chip IP Cores
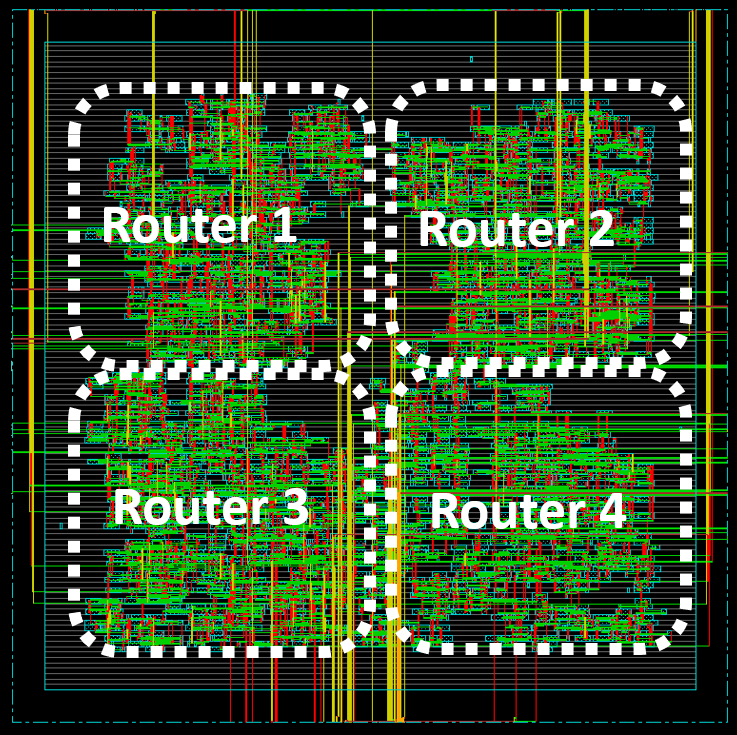
Toolset for enabling the Design and customized Network-on-Chip architectures. The software produces in automated way the synthesable Hardware Description Language (HDL) for the instantiated NoC. Tasks related to architecture-level exploration and optimization are also addressed within this tool.
Features:
- High-level topology exploration of NoC network
- Automated generation a reusable NoC architecture at RTL
- NoC customization in terms of routing algorithm (XY, LUT-based, …), number of router, selected topology (regular/irregular), buffer sizes, etc
Reference Paper
Request software tool for IP design & customization
a
Fault-Tolerance & Reliability Improvement
Open-source software tools that provide fault-tolerance and increased reliability to FPGA/ASIC platforms.
a
Fault-Free: Adaptive Fault-Tolerant Targeting FPGAs
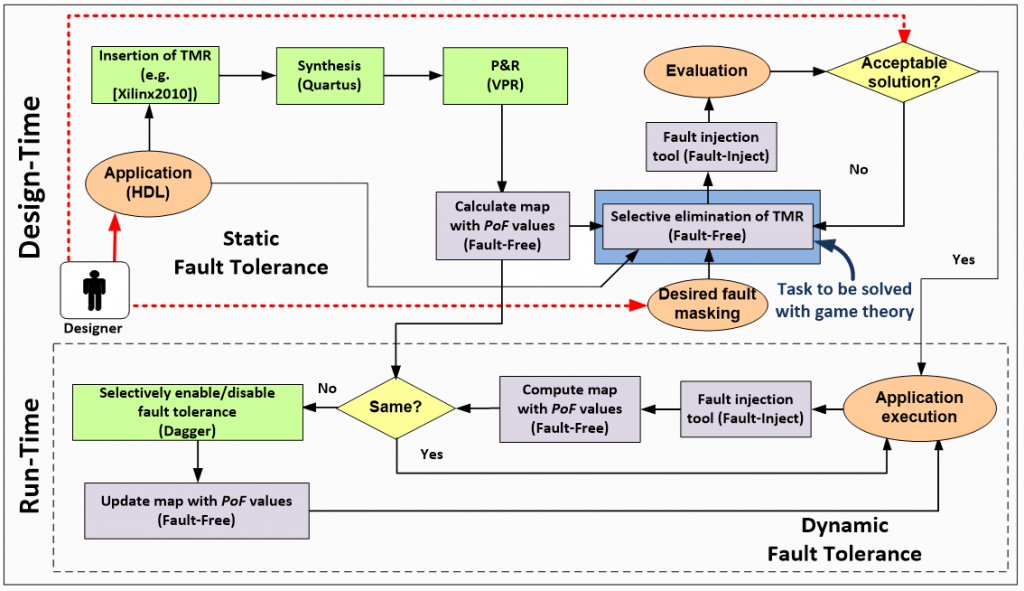
Software-supported methodology based on game theory for supporting the dynamic adaptation (at run-time) of fault tolerance. The toolset enables dynamic insertion and removal of redundancy depending on circuit’s and device’s inherent characteristics (e.g. on-chip temperature, switching activity, etc).
a
Fine-Tune Application’s Performance by Exploiting Process Variability
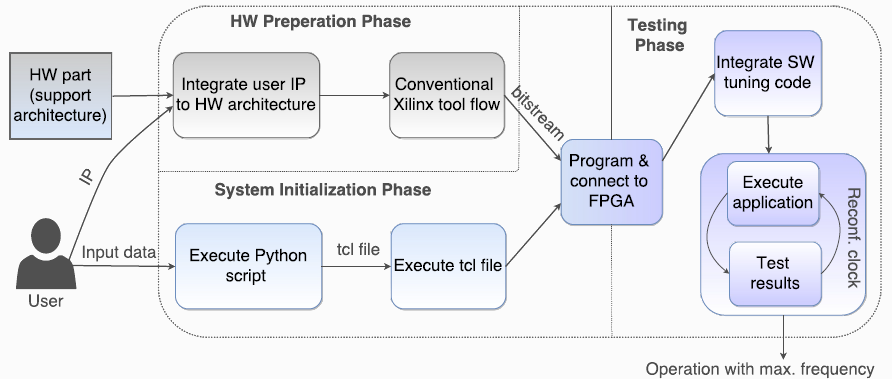
The toolset focuses on the variability effect in FPGAs and the possibility to boost the performance of each device at run-time, after fabrication, based on the individual characteristics of this device. For this purpose we develop a sensing infrastructure involving a wide network of customized ring oscillators to measure intra-chip and inter-chip variability for FPGA devices. Then, there is a closed-loop framework based on dynamic reconfiguration of clock tiles, I/O data sniffing, HW/SW communication, and verification with test vectors, to dynamically increase the operating frequency in Zynq while preserving its correctness.
a
Rapid Thermal Analysis of ICs
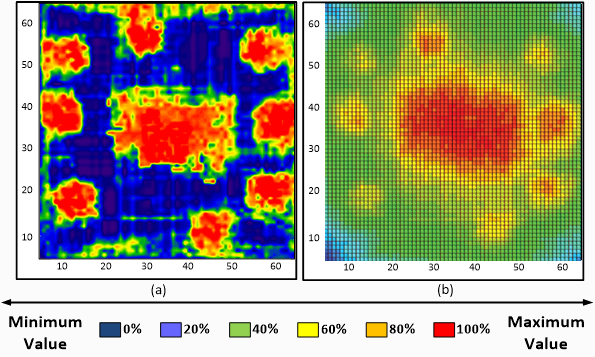
Detailed thermal analysis is usually performed exclusively at design time since it is a computationally intensive task. In contrast, this tool enables fast, yet accurate, thermal analysis for ICs/FPGAs.
Supported features:
- Architecture optimization through selective block replication.
- Eliminate thermal hotspots at SoCs.
- Alleviate temperature gradients.
- Provide multiple solution (pareto curve) that trade-off different design constraints/criteria.